
Split the Text files using ADF Pipelines
Inkey Solutions, November 29, 2024638 Views
Requirements:
If the file size of an Excel file exceeds the specified criteria, we need to address the following:
- The Excel file contains multiple sheets, and these sheets contain inter-related data.
- We utilize SQL Views to retrieve data from these sheets using the “Get Data” activity in Excel.
- Although we can split the Excel file using code to extract a specified number of rows in SQL queries, the requirement is to export the data from these Excel sheets to text files and split them accordingly.
For example, let’s consider two sheets:
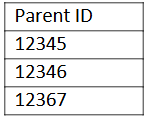
- Parent (Columns Name: Parent ID)
- Child (Columns Name: Parent ID, Child ID)
As mentioned in the point above, we use SQL Views, which means the data originates from SQL tables.
Parent table:
Child table:

Now, the additional requirement is that if we are splitting data from the 3rd row of the Parent table, then its matching records from the Child table should be in the same number of files.
For instance, if we split the file into two txt files named “Parent_1.txt” and “Parent_2.txt,” the corresponding Child files should be “Child_1.txt” and “Child_2.txt.” This ensures that whatever Parent ID is present in “Parent_1.txt,” its matching Parent ID should also be present in “Child_1.txt.”
So, the output files look like:
Parent_1.txt
Parent_2.txt

Child_1.txt

Child_2.txt

Implementation:
To Make this possible we used Stored Procedures, Views, and ADF Pipeline.
Let’s begin with the Stored procedure logic:
SP_Parent_Child_Split
CREATE PROCEDURE [dbo].[SP_Parent_Child_Split] /* Below variables will fetch the values from ADF Pipeline*/ @offset INT, @next INT AS /*Below code will first truncate the table and then insert the data in batches, it means every time it will truncate the data in this table. For example, we have 100 rows in Parent table, and we wanted to create two files so it will first insert 1 to 50 rows in this table in first iteration and then truncate this table and insert new data starting from 51 to 100. Note –Please create Parent_Splitting table same as Parent table first*/ TRUNCATE TABLE Parent_Splitting INSERT INTO Parent_Splitting SELECT DISTINCT P.[Parent_ID] AS ‘Parent ID’ /* Here we used Inner join because we need matching records in both Parent and Child in every part of files*/ FROM Parent P INNER JOIN vw_Child C ON C.Parent_ID=P.Parent_ID /* To use OFFSET ROWS, FETCH NEXT ROWS ONLY we must have to use ORDER BY CLUESE within it. OFFSET will start the fetching records from the given number of row and FETCH NEXT ROWS ONLY take the rows till the given number only. */ ORDER BY Parent_ID ASC OFFSET @offset ROWS FETCH NEXT @next ROWS ONLY GO
Views Logic:
vw_Parent:
CREATE VIEW [dbo].[vw_Parent] AS /* This will select data from Parent_Splitting table each time iteration run this will contains new records */ SELECT * FROM Parent_Splitting GO
vw_Child:
CREATE VIEW [dbo].[vwBOM_LSMW_Item] AS SELECT DISTINCT C.[Parent_ID] AS ‘Parent ID’ , C.[Child_ID] AS ‘Child ID’ FROM Child C
The following image (Image 1) shows ADF Pipeline activities to generate split txt files.

The next image (Image 2) shows a list of variables used in the pipeline.
Image 2:

Step 1: Lookup Activity
To get the total number of rows of the table, add a select query in the Query section of the Lookup activity in the setting option:
SELECT COUNT (Cln.Parent_ID) AS ‘RecordCount’ FROM Parent

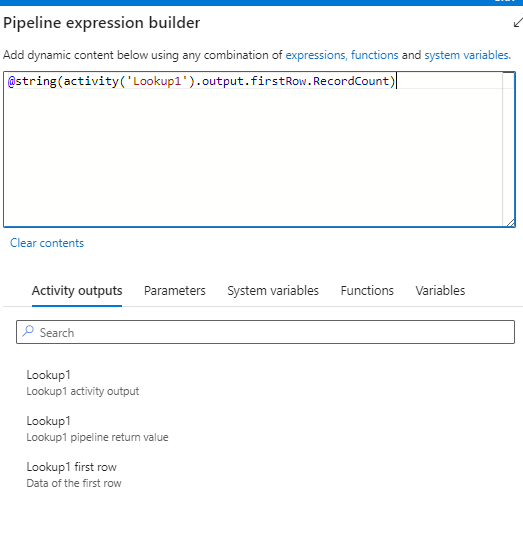
Step 2: Use Set Variable As shown in Image 1, name it “Record Count.” Go to the setting option, select the “RecordsCount” variable as shown in Image 2. In the pipeline expression builder, add the lookup activity, as shown below.
Step 3: Loop Count
Add one more set variable as shown in image 2. Select the “Loop Count” variable as shown in Image 1. Provide a number in the value section; it will split the files as per that value. For example, in the below image, we gave 2, so it will split the file into 2 txt files.

Step 4: Take another Set Variable, as shown in Image 1, named as “Start,” and select the “start” variable. Set the value field to 0.

tep 5: Take another Set Variable, as shown in Image 1, named as “End,” and select the “end” variable. In the value field, go to the dynamic expression and write the following code:
@string(div(int(variables('RecordCount')),int(variables('LoopCount'))))
This code will divide the total number of rows in the table by the number of files specified in Step 3. For example, if the total count of rows is 100 and you specified 2 files, it will divide 100 by 2 and split the data into two parts of 50 rows each.
Step 6: Utilize the “Until” activity and input the following expression. The “Counter” variable has an initial value of 0, as depicted in Image 1, and the “LoopCount” value is set to 2, as indicated in Step 3. This configuration ensures that the activity will iterate through the data until the value of “Counter” matches the value of “LoopCount.”
@equals(int(variables('Counter')),int(variables('LoopCount')))
This expression checks for equality between the current value of the “Counter” variable and the specified “LoopCount.” The activity will continue to iterate until this condition becomes true. In the given scenario, the loop will persist until the “Counter” variable reaches a value of 2, aligning with the specified “LoopCount.”
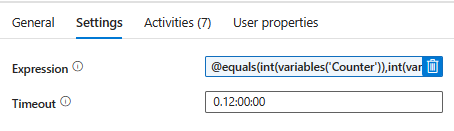
Image 3: Activities inside Until Loop

Step 7: Take another set variable inside until activity shown in image 3 named as “Counter Copy”.
Select “CounterCopy” in Name field and “Counter” variable in Value field in expression field.It will pass the value of “Counter” variable to “CounterCopy.”
So, when the loop will run the first time its value becomes 0 in this step.
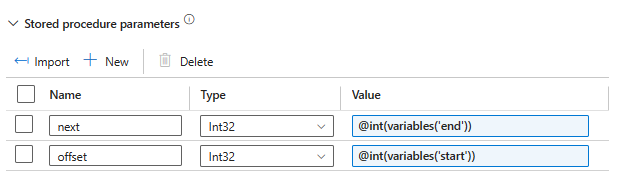
Step 8: Add the StoredProcedure activity as shown in Image 3 and select SP “SP_Parent_Child_Split” which was created in beginning of the implementation. Click on Import parameters arrow, and it will automatically fetch the parameters defined in stored procedure.
In the value section, incorporate the variables as demonstrated in the image below, using dynamic expressions. As clarified in Steps 4 and 5, the starting value of the “start” variable is 0, and the value of the “end” is 50. Therefore, during the first iteration, it will read the data from rows 1 to 50.
Step 9: Implement a Copy activities to transfer data from Views to text files for both Parent and Child.
Create the source dataset for both, pointing to the SQL views (vw_Child, vw_Parent).
Next, create two sink datasets, one for Parent and one for Child, both of tab-delimited type. In both datasets, establish parameters as demonstrated in the image below. These parameters will be used to configure the dynamic aspects of the datasets.
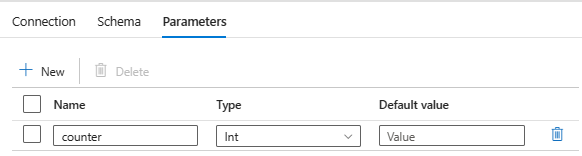
After creating the sink datasets for Parent and Child, proceed with the following steps: 1. Go to the Connection section again and provide the dynamic expression in the filename field:
@concat('Parent_',string(dataset().counter),'.txt')
This expression will concatenate “Parent_” string with the dynamic count value which will comes from Pipeline [string(dataset(). counter) -This is the parameter which we created at dataset level shown in above image so select that parameter here] and at the end will concatenate “.txt” extension with it.
So, it will generate the file name like this: Parent_1.txt, Parent_2.txt and so on.
Navigate to the Pipeline section and include two Copy activities. Configure the source and sink using the datasets created earlier.
In the Sink section of the copy activities, as parameters were created in the “Txt” datasets, these parameters will be visible here. Add the value of one to the “Counter” variable. For example, if the counter variable was 0 initially, it will become 1. During the first iteration of the loop, this will generate file names like Parent_1.txt.
This process ensures that each iteration of the loop produces unique file names based on the dynamic counter value, allowing for the creation of Parent_1.txt, Parent_2.txt, and so forth.

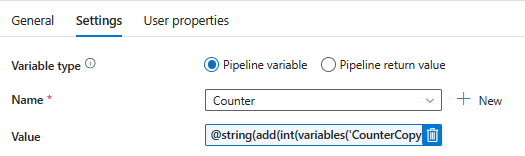
Step 10: After copy activities of both Parent and Child add Set variable as shown in image 3, select “Counter” variable in name section and in value field select ‘CounterCopy’ variable and start adding value by 1 as did it for dynamic name of files.
@string(add(int(variables('CounterCopy')),1))
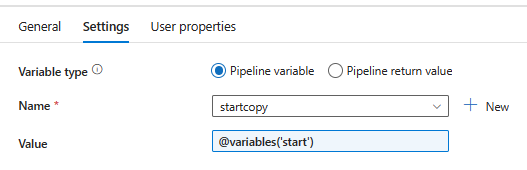
Step 11: Take another Set Variable, as shown in Image 3, named “StartCopy” and select the “startcopy” variable. Assign the value of the “start” variable to it, as demonstrated in the image. This step essentially captures and copies the value of the “start” variable for further use.
Step 12: Next, take one more Set Variable, as shown in Image 3, named “Start,” and select the “start” variable. Add the value of the “end” variable to the “start” variable. The expression for this step is:
@string(add(int(variables('startcopy')),int(variables('end'))))
This calculation ensures that the next iteration starts from where the previous iteration ended. In this example, the value of the “start” variable becomes 50.









