How to Build a Pipeline for Exact Matching in Azure ML Using Python Script
Inkey Solutions, December 27, 2024584 Views
Exact matching is a critical process for identifying precise matches between text data and predefined keywords. In this blog, we’ll walk you through building an Azure ML pipeline to perform exact keyword matching using a Python script
Why Perform Exact Matching?
Exact matching is vital when precision is critical. It ensures:
- Identifying Specific Terms: Ideal for identifying predefined terms like product names or SKUs.
- Avoiding False Positives: By making the comparison case-sensitive and exact, we avoid incorrect matches like “Wood” matching “WOOD.”
Here’s a step-by-step guide to help you understand and replicate the process.
Step 1: Understand the Datasets
The process begins with two datasets:
- Text Dataset: This contains the textual data to compare with the keywords.
- Keyword Dataset: This holds the keywords for matching, along with a column IsMatch to indicate if the keyword is flagged for exact matching.
Both datasets are passed as inputs to the Python scripts in the pipeline. The Text Dataset is used for matching, and the Keyword Dataset provides the keywords.
Step 2: Implement the Python Script for Exact Matching
Step-by-Step Explanation
Input Datasets
The script uses two input datasets:
- Text Dataset: Contains the text data to be analyzed.
- Keyword Dataset: Holds keywords to match against the text data.
Install Required Libraries
Essential libraries like pandas, numpy, and re are installed and imported to ensure the script functions efficiently.
Preprocessing Function
This function cleans both the text and keyword data by:
- Removing special characters.
- Eliminating extra spaces.
This step prepares the data for accurate matching.
Exact Matching Logic
The script performs exact matching of keywords to text data using:
Case-sensitive comparison: Ensures matches are precise.
Regex: Identifies only exact matches to avoid false positives.
Processing the Text Dataset
- Renames the text column for clarity.
- Applies the preprocessing function to clean the text.
- Initializes columns for storing matching results (ContainsKeyword and MatchingKeywords).
Processing the Keyword Dataset
- Renames and preprocesses the keyword column.
- Filters the dataset to include only rows where IsMatch = 1.
- This reduces unnecessary computations.
Generating the Output
- Populates the ContainsKeyword and MatchingKeywords columns for matched rows.
- Produces the final output with original text and matched keywords (assigned_labels).
- Confidence score set to 1.0.
# Azure ML entry point function
def azureml_main(dataframe1=None, dataframe2=None):
import subprocess
import sys
def install(package):
subprocess.check_call([sys.executable, "-m", "pip", "install", package])
# Install required packages
install('sentence-transformers')
install('numpy')
install('scikit-learn')
install('pandas')
# Importing libraries
import pandas as pd
import re
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
def exactmatch_preprocess_text(text):
text = re.sub(r'\W', ' ', text)
text = re.sub(r'\s+', ' ', text)
return text
def exact_matching(text_df_match, label_df_match, cln_text_col, cln_label_col, label_col):
any_matches_found = False
for index, row in label_df_match.iterrows():
keyword = row[cln_label_col]
matches = pd.Series([False] * len(text_df_match), index=text_df_match.index)
pattern = r'^\b' + re.escape(keyword) + r'\b$'
matches = text_df_match[cln_text_col].apply(lambda x: bool(re.fullmatch(pattern, x)))
if matches.any():
any_matches_found = True
text_df_match.loc[matches, "ContainsKeyword"] = True
text_df_match.loc[matches, "MatchingKeywords"] = text_df_match.loc[matches, "MatchingKeywords"]+row[label_col]
return text_df_match
# Processing the Text Dataset
text_df_match = dataframe1[['Desc']].rename(columns={'Desc': 'text'})
text_df_match['cleaned_text'] = text_df_match['text'].apply(exactmatch_preprocess_text)
# Processing the Keyword Dataset
label_df_match = dataframe2.rename(columns={'Keyword': 'label'})
label_df_match['cleaned_keyword'] = label_df_match['label'].apply(exactmatch_preprocess_text)
label_df_match = label_df_match[label_df_match['IsMatch'] == 1].reset_index(drop=True)
# Initialize ContainsKeyword and MatchingKeywords columns
text_df_match['ContainsKeyword'] = False
text_df_match['MatchingKeywords'] = ''
# Apply Exact Match Logic
text_df_match = exact_matching(text_df_match,label_df_match,'cleaned_text','cleaned_keyword','label')
exact_match_condition = (text_df_match["ContainsKeyword"] == True)
# Extract rows with matches
exact_match_df = text_df_match.loc[exact_match_condition, ['text', 'MatchingKeywords']]
# Prepare the final output
exact_match_df.reset_index(inplace = True, drop = True)
exact_match_df.rename(columns = {'MatchingKeywords':'assigned_labels'}, inplace = True)
exact_match_df['confidence_score'] = 1.0
# Ensure correct data types
exact_match_df = exact_match_df.astype({
'text': 'string', # Ensure text is of string type
'assigned_labels': 'string', # Assign labels as string
'confidence_score': 'float' # Set confidence score as float
})
return exact_match_df,
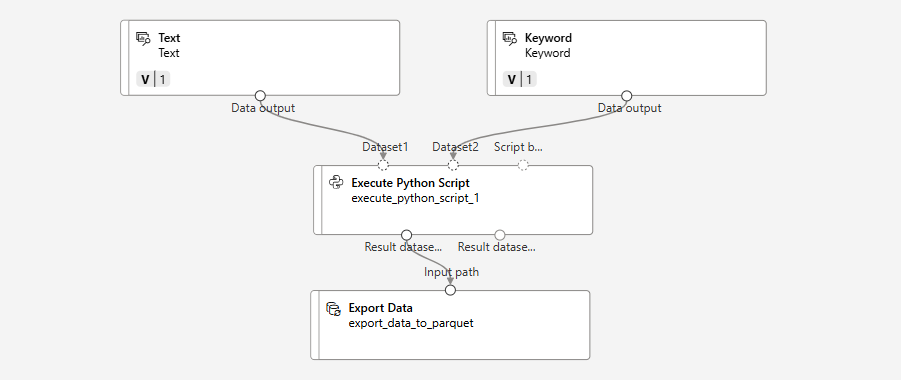
The image below showcases the Designer view of the Azure ML Pipeline: